# 调优指南
{% hint style="info" %}
**机器学习**的训练过程相对比较复杂。
生成不同的特征,不同的模型,不同的模型参数,不同的验证集等等都会导致模型的效果不同。 这里主要介绍如何使用ChangTianML调优,以及如何得到基于您数据集最优的模型。
**您可以按照顺序依次调整ChangTianML中的配置。**
{% endhint %}
## 一. 设置合适的验证集比例
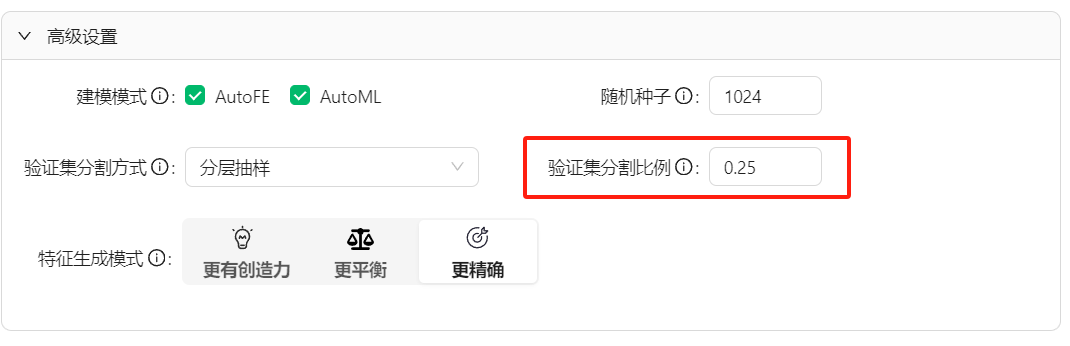 由于验证集是由整体数据集切分得来的,剩下的数据就是训练集,所以验证集和训练集就是**零和关系**。
验证集变大那么训练集就会变小,如果训练集太小那么可能会导致**模型拟合不足**甚至**性能不佳**。反之,验证集如果太小,它可能无法准确反映现实世界数据的真实分布。 这可能会导致**过度拟合**,即模型在训练集上表现出色,但在验证集上表现不佳,更重要的是,在未见过的数据上表现不佳。
{% hint style="info" %}
**调整方式**
(1)默认的是**0.25**的验证集比例,这是根据常见的数据所集设置的。
(2) 如果模型拟合的效果不好,可以首先调整这个比例,这里建议**调整的范围在0.1-0.3**之间。
{% endhint %}
## 二. 自动机器学习-最大尝试时长(秒)
{% hint style="info" %}
ChangTianML自动机器学习是按照**时间**进行最佳模型的探索,增加**最大尝试时长**,模型探索的路径会更加深入,可能会找到更优的模型。
{% endhint %}
由于验证集是由整体数据集切分得来的,剩下的数据就是训练集,所以验证集和训练集就是**零和关系**。
验证集变大那么训练集就会变小,如果训练集太小那么可能会导致**模型拟合不足**甚至**性能不佳**。反之,验证集如果太小,它可能无法准确反映现实世界数据的真实分布。 这可能会导致**过度拟合**,即模型在训练集上表现出色,但在验证集上表现不佳,更重要的是,在未见过的数据上表现不佳。
{% hint style="info" %}
**调整方式**
(1)默认的是**0.25**的验证集比例,这是根据常见的数据所集设置的。
(2) 如果模型拟合的效果不好,可以首先调整这个比例,这里建议**调整的范围在0.1-0.3**之间。
{% endhint %}
## 二. 自动机器学习-最大尝试时长(秒)
{% hint style="info" %}
ChangTianML自动机器学习是按照**时间**进行最佳模型的探索,增加**最大尝试时长**,模型探索的路径会更加深入,可能会找到更优的模型。
{% endhint %}
.png?alt=media&token=cc875ed9-894f-48ec-9705-15f3c5537fbd) 由于资源限制,目前**自动机器学习-最大尝试时长(秒)** 最高支持600秒。
## 三. 自动特征工程-最大实验次数
{% hint style="info" %}
ChangTianML自动化特征工程会根据设置的最大实验次数去深度捆绑特征,当设置得越大,那么搜索的范围越大,越有可能搜索到有效特征。
{% endhint %}
由于资源限制,目前**自动机器学习-最大尝试时长(秒)** 最高支持600秒。
## 三. 自动特征工程-最大实验次数
{% hint style="info" %}
ChangTianML自动化特征工程会根据设置的最大实验次数去深度捆绑特征,当设置得越大,那么搜索的范围越大,越有可能搜索到有效特征。
{% endhint %}
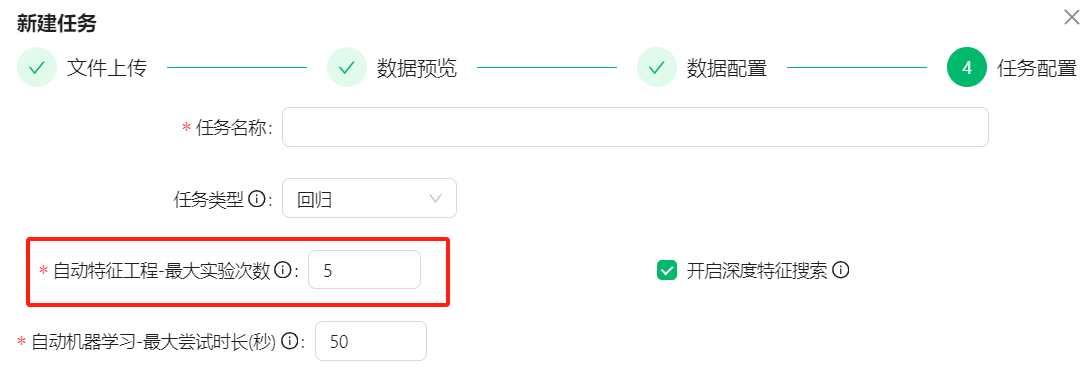 由于资源限制,目前**自动特征工程-最大实验次数**最高支持10次。
## 四. 特征生成模式
{% hint style="info" %}
**更有创造力**模式可能会探索并生成更多特征组合。
**更精确**模式在探索特征时以准确性为优先。
**更平衡**模式介于二者之间。
{% endhint %}
由于资源限制,目前**自动特征工程-最大实验次数**最高支持10次。
## 四. 特征生成模式
{% hint style="info" %}
**更有创造力**模式可能会探索并生成更多特征组合。
**更精确**模式在探索特征时以准确性为优先。
**更平衡**模式介于二者之间。
{% endhint %}
 如果高级特征生成得较少,那么可以选择**更有创造力模型**,这会让算法更主动地寻找高级有效特征,为模型提供更多信息,从而得到更好的模型效果。
如果高级特征生成得较多,那么可以选择**更有精确模型**,这会让算法更严谨地寻找高级有效特征,降低模型过拟合的风险,提高模型的鲁棒性。
## 五. 深度特征搜索
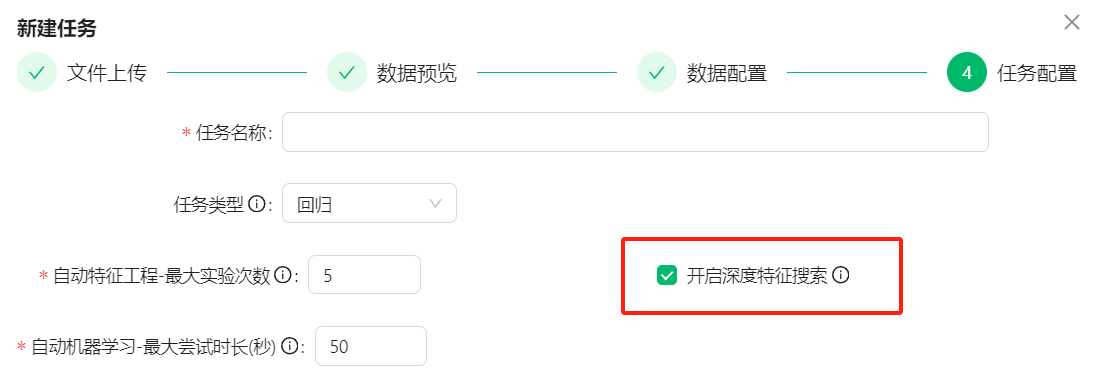
**特征搜索**是一个无限空间内进行的,例如:特征A和B组合成一个C的特征,特征C和A还可以组合成D特征等等,那么开启深度搜索可能得到更深层次的特征。
如果高级特征生成得较少,那么可以选择**更有创造力模型**,这会让算法更主动地寻找高级有效特征,为模型提供更多信息,从而得到更好的模型效果。
如果高级特征生成得较多,那么可以选择**更有精确模型**,这会让算法更严谨地寻找高级有效特征,降低模型过拟合的风险,提高模型的鲁棒性。
## 五. 深度特征搜索
**特征搜索**是一个无限空间内进行的,例如:特征A和B组合成一个C的特征,特征C和A还可以组合成D特征等等,那么开启深度搜索可能得到更深层次的特征。
 ## 六. 数据配置
**检查数据**是一个非常重要的步骤,平台上会根据整体的数据从统计学上给出一个初步判断,但从实际物理意义上不一定是完全正确的。检查可以从两个方面。
* **列特征**:特别需要注意的是,id类有多种,**唯一标识的id列需要忽略**否则可能造成过拟合。对于时间序列的任务,时间列索引和时间组标识需要配置好。
* **是否类别特征**:由于特征捆绑中类别和数值特征的方式不同,以及对机器学习模型也有较大的影响,所以请确认特征是否为类别特征。
## 六. 数据配置
**检查数据**是一个非常重要的步骤,平台上会根据整体的数据从统计学上给出一个初步判断,但从实际物理意义上不一定是完全正确的。检查可以从两个方面。
* **列特征**:特别需要注意的是,id类有多种,**唯一标识的id列需要忽略**否则可能造成过拟合。对于时间序列的任务,时间列索引和时间组标识需要配置好。
* **是否类别特征**:由于特征捆绑中类别和数值特征的方式不同,以及对机器学习模型也有较大的影响,所以请确认特征是否为类别特征。
